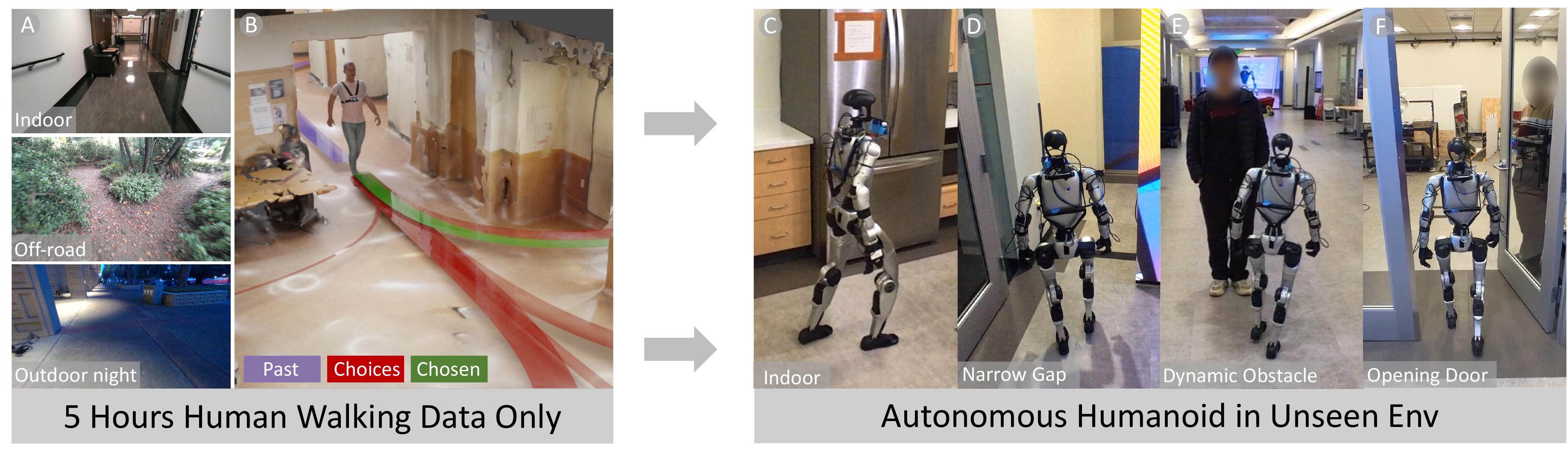
We present EgoNav, a system that enables a humanoid robot to traverse diverse, unseen environments by learning entirely from human walking data, with no robot data or finetuning. A diffusion model predicts distributions of plausible future trajectories conditioned on past trajectory, a 360° visual memory fusing color, depth, and semantics, and video features from a frozen DINOv3 backbone that capture appearance cues invisible to depth sensors. A hybrid sampling scheme achieves real-time inference in 10 denoising steps, and a receding-horizon controller selects paths from the predicted distribution. We validate EgoNav through offline evaluations, where it outperforms baselines in collision avoidance and multi-modal coverage, and through zero-shot deployment on a Unitree G1 humanoid across unseen indoor and outdoor environments. Behaviors such as waiting for doors to open, navigating around pedestrians, and avoiding glass walls emerge naturally from the learned prior. We release the dataset and trained models.
Corridor
Door Opening 1
Door Opening 2
Glass Wall
Kitchen (Clean)
Kitchen (Cluttered)
Crowd
Room (Cluttered 1)
Room (Cluttered 2)
300 minutes (5 hours) of human walking data covering 25+ km across diverse campus environments. 44 sequences at 20 Hz, spanning varied weather, surfaces, and dynamic obstacles. Each timestep provides 6-DoF pose, RGBD images, semantic segmentation (8 classes), and precomputed visual memory panoramas. Dataset and pretrained models will be released after review.
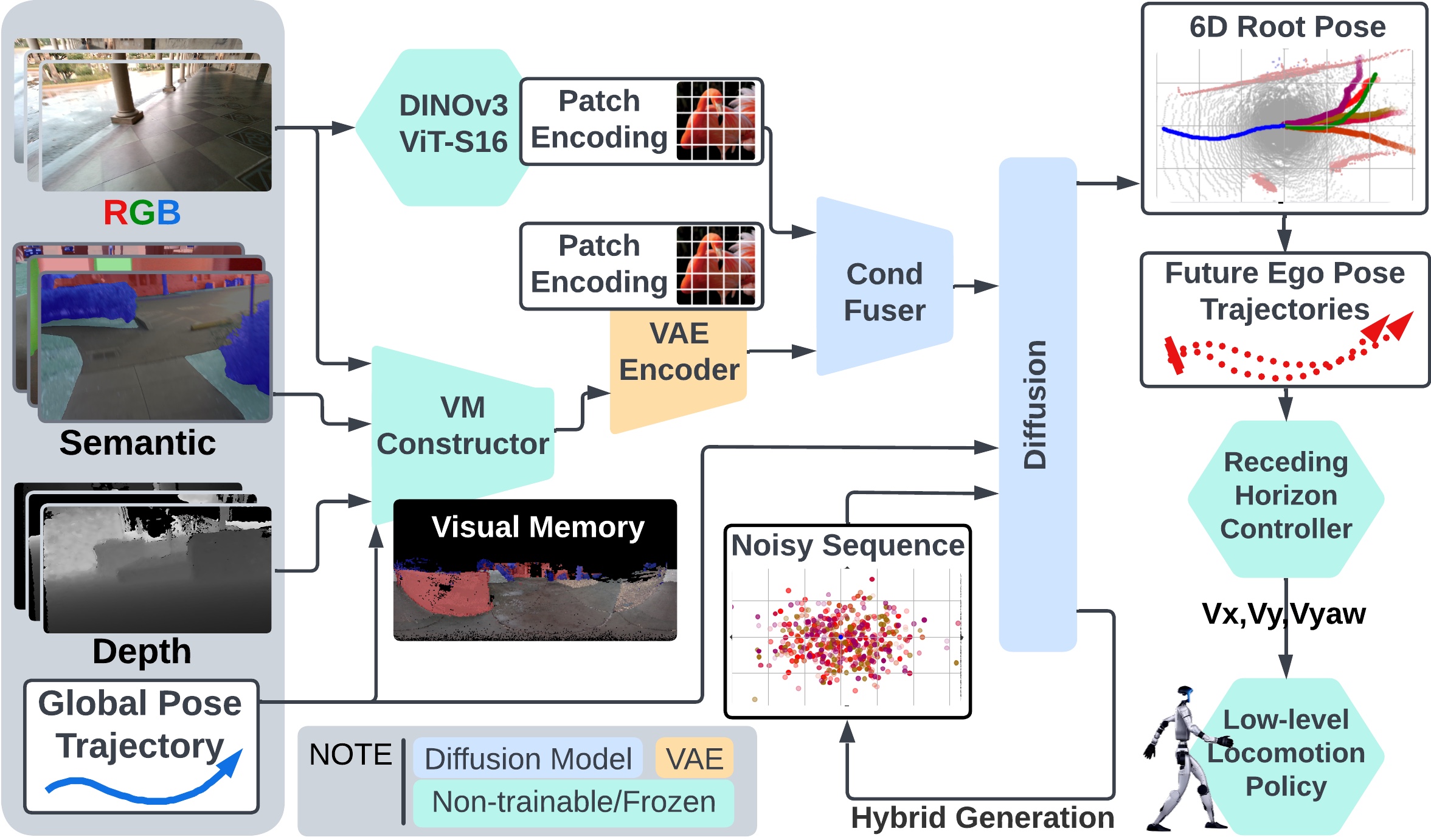
EgoNav learns a navigation prior—an embodiment-agnostic distribution of plausible future paths—bridging high-level planning and low-level locomotion. The system is human-native (no robot data), scene-aware (egocentric observations only), distributional (multi-modal predictions), and robot-ready (real-time with latency compensation).
Given past trajectory and RGBD history, frames are semantically labeled into 8 classes and fused into a 360° egocentric panorama ("visual memory"). A frozen DINOv3 backbone captures appearance cues invisible to depth (glass walls, dynamic agents). A diffusion model generates trajectory distributions, and a receding-horizon controller selects collision-free paths for deployment.
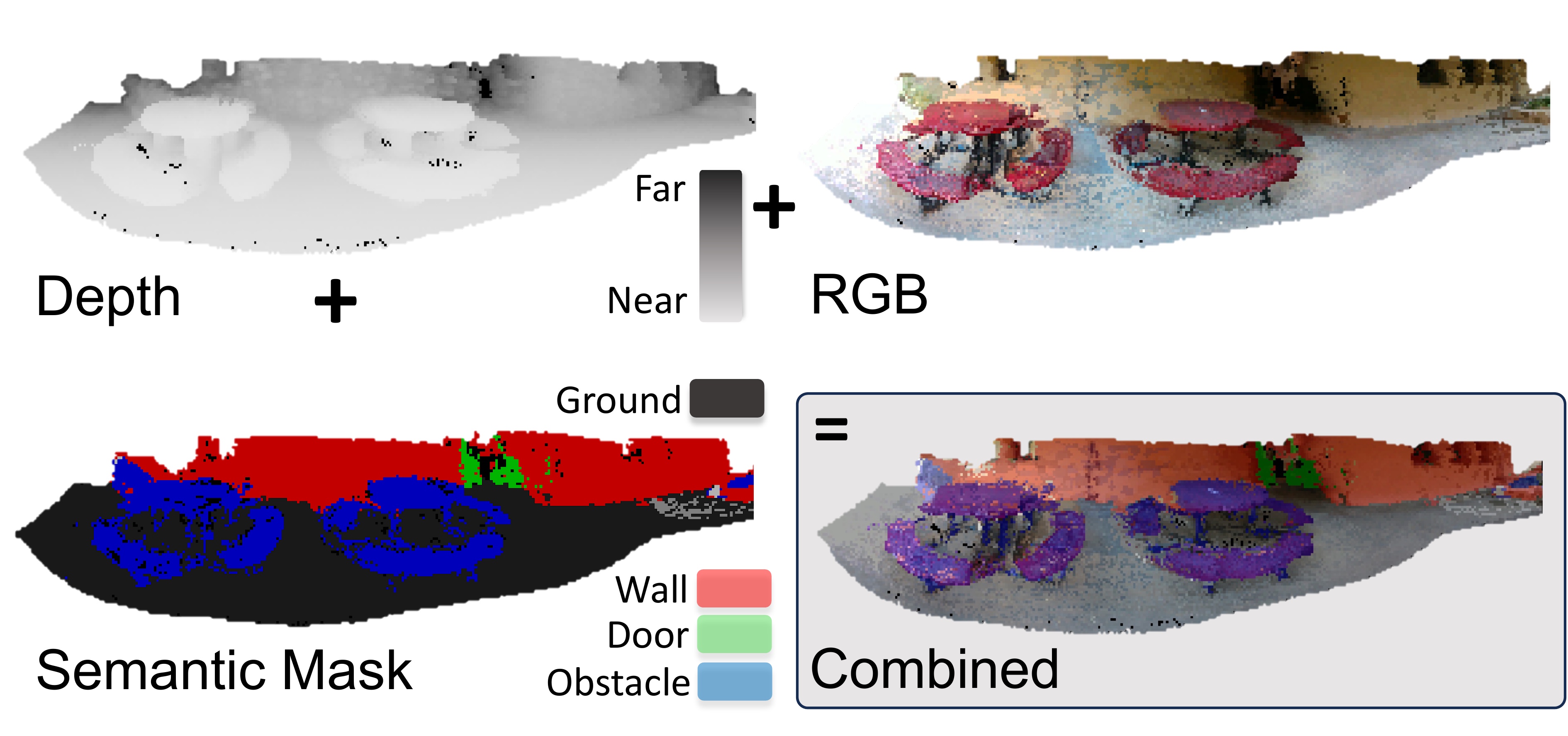
A 360° panoramic representation (180×360×5) fusing RGB, depth, and semantic channels. RGBD frames are accumulated into a point cloud, filtered by distance, and reprojected into the current egocentric frame. Encoded by a pretrained spatial VAE into a 64-dim embedding, running within 30ms on a Jetson Orin NX. Compared to a single ~90° FOV camera, the visual memory captures far more scene context in one compact representation.

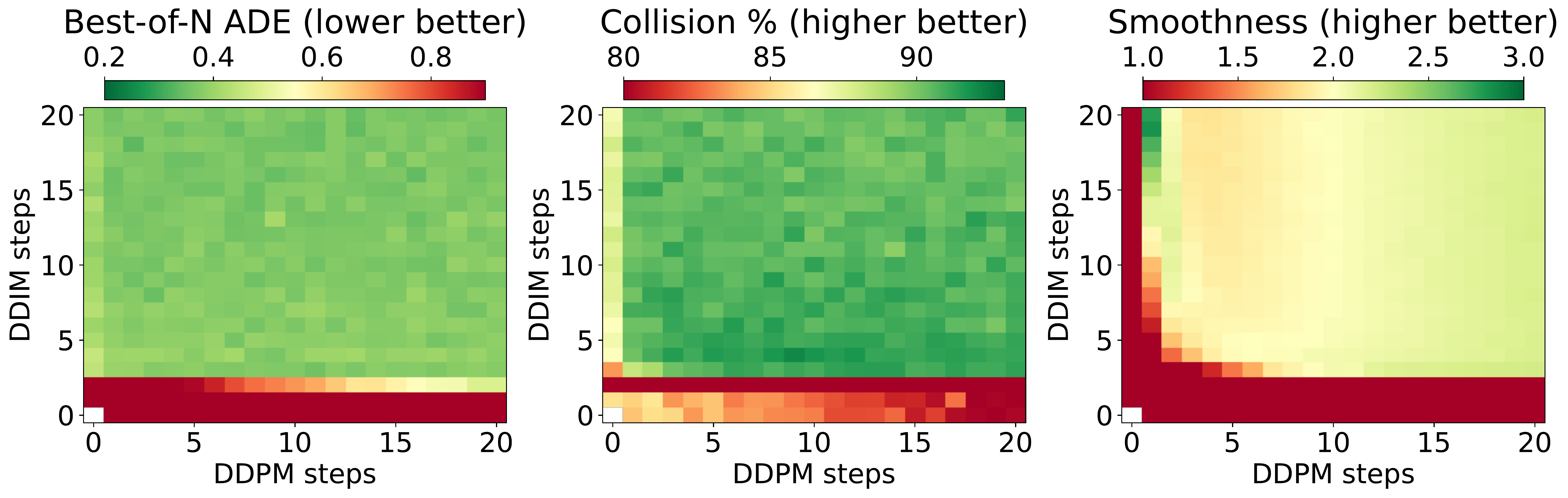
Hybrid generation step search: Best-of-N, Collision, and Smoothness scores for different DDIM/DDPM step combinations. The optimal configuration is 5 DDIM + 5 DDPM steps.
A 46M-parameter UNet predicts all 100 future steps (5 sec at 20 Hz) non-autoregressively, conditioned on visual memory, DINOv3 features, and past trajectory via classifier-free guidance. Our hybrid scheme—5 DDIM steps followed by 5 DDPM steps—achieves 100× acceleration over full DDPM while preserving multi-modal quality, generating 110 trajectories/sec at 1.7 Hz on a Jetson Thor.
Zero-shot deployment on a Unitree G1 humanoid: 37.5 minutes, 1,137 meters, over 96% autonomous across static, corridor, glass, and dynamic scenes. Emergent behaviors include waiting at doors, navigating around pedestrians, and avoiding glass walls.
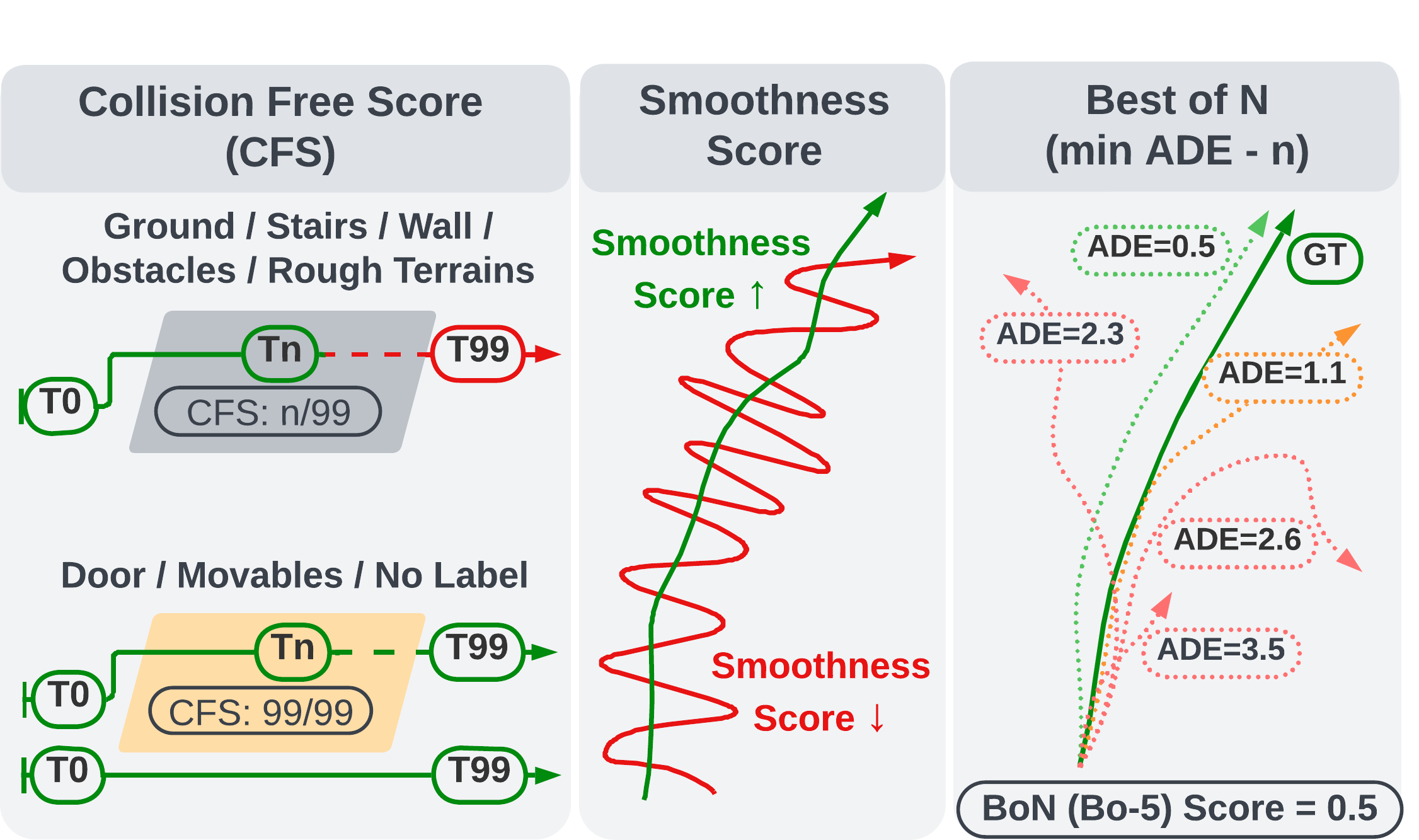
Three metrics: Collision-Free Score (CFS), Smoothness, and Best-of-N (minADE-K).
Each component contributes meaningfully: semantic channel −5.1 collision (can't distinguish doors from walls), attention −2.6, and DINOv3 features prove critical in real-world glass/dynamic scenes despite modest offline gains.
@article{wang2026egonav,
title={Learning Humanoid Navigation from Human Data},
author = {Wang, Weizhuo and Ze, Yanjie and Liu, C. Karen and Kennedy III, Monroe},
journal={IEEE Robotics and Automation Letters},
year={2026},
}